The Frequency Domain: Or, There and Back Again
August 2022 (5863 Words, 33 Minutes)
Some Context
Hi, I’m Oleg, a freshly graduated games programming bachelor of science student! I’m actively specializing in game audio programming and I wish to share with you a little visualization I’ve made to better understand the concept of audio signals in the frequency-domain, the Discrete Fourier Transform (DFT) and it’s inverse operation, the Inverse Discrete Fourier Transform (IDFT).
As part of my last year of studies, I’ve looked into binaural sound spatialization and in doing so have encountered these then-foreign concepts. For the purposes of my bachelor’s degree, I’ve contented myself with seeing the frequency domain as a nebulous and arcane space that just allows to “do some mathematical magic” so to speak, and have viewed the DFT and IDFT as black-boxes that do “mathematical magic stuff” to travel there and back to the time domain.
But what do these black-boxes actually do? And what is this mystical space all of those academic papers keep talking about?
Credits
First things first, this blogpost uses various images, the sources of which have been marked below them. These include the works of talented artists, graphs from useful academic publications and screen captures of the excellent The LotR and The Hobbit movies. I encourage you to follow those links! All of these media are used here solely for educational purposes, no monetary gain is made from this blogpost.
Also, I have provided the reader with software they can use to explore the subject at hand and it would have not been possible without the following libraries, softwares and services, in no particular order:
- Visual Studio 2019
- Git and Github
- CMake
- David Reid’s dr_wav
- Sergey Yagovtsev’s easy_profiler
- Omar’s Dear ImGui
- PortAudio
- Simple Directmedia Layer 2 (SDL)
- Dmitry Ivanov’s Simple-FFT
Although not all necessarily mentioned in the text, the following resources were very useful to familiarize myself with the subject of this blogpost and I encourage you to read / watch them yourself:
- Wikipedia, of course.
- 3Blue1Brown’s excellent youtube channel, who is great at giving the viewer an intuition for complicated mathematical subjects. Three of his videos are particularly useful on the subject: “But what is the Fourier Transform? A visual introduction.”, “But what is a Fourier series? From heat flow to drawing with circles DE4” and “What is Euler’s formula actually saying? Ep. 4 Lockdown live math”.
- Steve Brunton’s a bit more mathematically oriented but still comprehensive videos exploring the Fourier Transform, namely the videos “The Fourier Transform” and “The Discrete Fourier Transform (DFT)”.
- Reducible’s equally mathematically focused video explaining the FFT: “The Fast Fourier Transform (FFT): Most Ingenious Algorithm Ever?”.
- SmarterEveryDay’s “What is a Fourier Series? (Explained by drawing circles) - Smarter Every Day 205” video inspired by Bilgecan Dede’s blogpost.
- Eugene Khutoryansky’s excellent visualization: “Fourier Transform, Fourier Series, and frequency spectrum”.
- And finally, Akash Murthy’s criminally underrated whole youtube channel.
Finally, a disclaimer: I myself am by no means an expert on this subject. I have done everything I could to ensure that the information presented here is factual, but if you do spot errors, feel free to message me at loshkin.oleg.95@gmail.com .
The Time Domain

“Rivendel” by Ivan Cavini.
First, before talking about the frequency domain, let’s make clear what a “regular” sound signal looks like, one that is in the time domain. You’ve obviously seen the following waveforms, be it in an youtube entertainer’s video making clever japes about their editing skills, or you maybe have already played with them yourself in a video or audio editing application, such as Audacity:

This is a time-domain representation of a sound signal, and if we zoom in, we can see that it’s just a sequence of equally spaced so-called “samples”:

The left-to-right axis represents increasing time, and the horizontal axis indicates a normalized instantaneous air pressure that the microphone has recorded at that moment. We can clearly see the “impulse train” that forms the digital signal. For more info about sampling, check out this Akash Murthy’s excellent video. This representation of a sound is very useful for some types of analysis, for generating a so-called “envelope” of the signal for instance, which can be very useful to describe the “timbre” or “color” of a sound.
The Frequency Domain

“Wraith World” by Paul Lasaine.
While a time-domain signal has its uses for analysis, it is not obvious from this representation alone to visualize what frequencies compose the sound and to what extent each of them influence the sound to end up with this complex signal.
This is where the frequency-domain representation comes in: it allows us to make the signal reveal its hidden secrets! In theory, we can map the real-valued, time-domain signal to the frequency domain via the Discrete Fourier Transform. What we’ll end up is the same signal, but this time, instead of the left-to-right axis encoding the signal’s evolution in time, it represents which pure tones of each frequency would be needed to get back the original time-domain signal, how much of them would be needed, and at what phase offset.
The most common way to represent a signal in the frequency domain is via the use of a so-called “Audio Power Spectrum”:
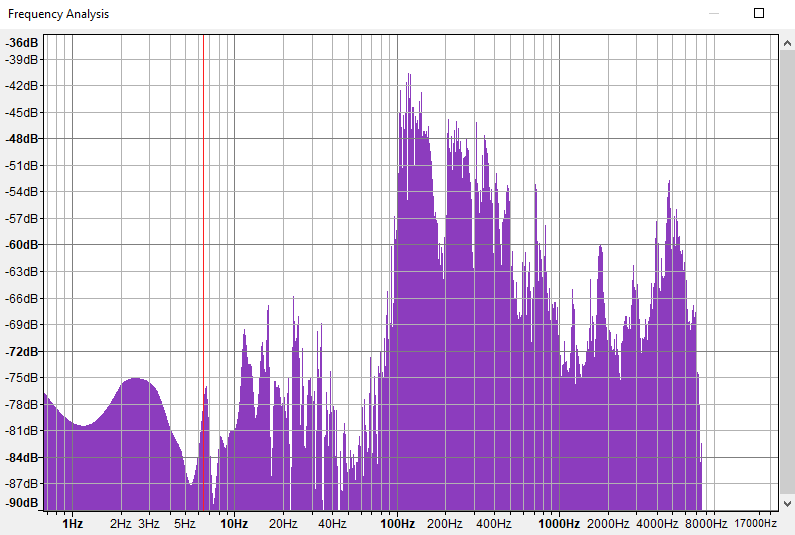
This graph allows us to see what frequencies compose our time-domain signal and at what intensities (here measured in dB’s) but does not show us the phase offsets of these frequencies. Another way to visualize the frequency-domain representation of a signal, while preserving the phase offset information is via the use of a Bode plot (pronounced as “boh-dae”):
Example of an unrelated Bode plot taken from a Kollmorgen blogpost explaining Phase Margin.
In such a graph, all the information is preserved and available for analysis but it is (as of the knowledge of the author) seldom used for audio editing, at least in DAW’s. There is an observation to be made here however: there needs to be three independent axes to fully represent the Fourier Transform, like say, a simple 3D plot, wink wink! In fact, such a visualization is exactly what is used in this blogpost, but I’m getting ahead of myself.
The Discrete Fourier Transform

“The One Ring” by Thorbear.
So, we now know about these two parallel realms, so to speak, in which a signal can live, but the question is: how do we get from one to the other (and back)? Well, this is where we can introduce the Fourier Transform, or in the case of discrete signal processing, the Discrete Fourier Transform, which does the same thing as the regular Fourier Transform, but takes as input a finite, discrete signal rather than an infinite continuous one. For the sake of brevity, from now on I’ll be referring to the Discrete Fourier Transform simply as the “DFT”. First of all, the DFT, as its name indicates, is a mathematical transformation, meaning it maps a set of values from one space to another. In the case of the DFT, it maps a real-valued signal to the Argand plane, the plane where all the real and complex numbers live.

“Complex Plane” from an article by www.mathsisfun.com.
As a reminder, a complex number is one that has two components: a real component and an imaginary component. This can be written as:
![]()
or simply:
![]()
Here, “real” and “imag” are both ordinary reals, but by the very definition of i we know that these two components are orthogonal: there simply by definition is no real number that satisfies the equation:
![]()
This is well and dandy, but it isn’t of much use to us until we realize that:
![]()
As well as:
![]()
What does that mean? It means that complex numbers can be used to represent rotations in a very useful manner. And why do we care about that? Because pure tones are sinusoidal functions, periodic ones that can represent a rotation! All of this is quite hard to understand when all of this is put in such a mathematical way so quickly, but 3Blue1Brown’s “What is Euler’s formula actually saying? | Ep. 4 Lockdown live math” explains the concept very well if you want to better understand these formulas. This property can be used to make many mappings between the domain of reals and the domain of complex numbers, but one mapping is particularly useful, the DFT:
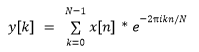
This function looks quite scary for those that are not used to working with mathematical formulas beyond those encountered in high-school but if we split it into separate components, we can easily explain what the function does. First, “y[k]” is the output of the function and yields what is known as a “frequency bin”, that is, a complex number that defines for any given sinusoid of frequency “n”, what magnitude it should have and what phase. The “[]” are here to indicate that “y” is an array of numbers, in our case, an array where each number represents a sine frequency. The whole array y is what is usually referred to as “the” Fourier Transform of the input signal “x” and defines what pure tones would be needed at what intensity and at what phase offsets in order to reconstruct the original time-domain signal.
![]()
This part is simply used to indicate that what comes rightwards of the equation is a sum where the variable “k” ranges between 0, inclusive, and an arbitrary number “N”, exclusive. Similarly to “y[k]” which represents a single element of the output array, “x[n]” represents the real value of a given sample of a time-domain signal.
![]()
Finally, this bizarre looking expression represents an exponentiation of the Euler’s number to a power of an imaginary number. The Euler’s number isn’t much trouble in itself, it’s just an irrational constant, just like pi. The troubling part is: how do you raise e to an imaginary power? What does that even mean? Well, firstly, let’s make clear something very important. We’ve all been taught that raising a number “x” to a power “y” is equivalent to multiplying “x” by itself y times. With “x” = 2 and “y” = 3 for example, we’d end up with:
![]()
This is NOT what is meant with “e” raised to a power of “x”. This can create a lot of confusion, but that is not how exponentiation is defined for Euler’s number, instead it is defined as a so-called “convergent series”, the details of which you can find in this excellent youtube by 3Blue1Brown, once again. We will not go into explaining this convergent series but instead will refer to a very handy mathematical identity that will get us out of this roadblock:
![]()
Meet [Euler’s formula] (https://en.wikipedia.org/wiki/Euler%27s_formula) (or identity). It is remarkable in that it allows us to represent a rotation on a unit circle as an exponentiation operation of “e” to an imaginary power “ix”. For instance, we can compute a 360° rotation on the unit circle in the Argand plane as:
![]()
Computing “e” raised to the power “2pii” is quite confusing unless you have a good background in mathematics, but computing “cos(2pi)” and “sin(2pi)” is trivial:
![]()
As expected, if we rotate a point defined by “1+0i” by 360°, we should indeed end up back at “1+0i”:

Why is that useful? Well, armed with this identity, we can rewrite the very confusing part of the DFT equations as:
![]()
Now the scary part of the equation has become trivial: it’s just a bunch of constants and real-valued variables plugged into a couple of trigonomic functions! And with all of that in hand, we should now be able to code our own DFT algorithm implementation!
The Visualizer

“Saruman consulting the Palantir” from “Lord of the Rings: The Fellowship of the Ring” (2001) retrieved from a Business Insider article.
Now, with the theory out of the way, let’s get to coding! First, clone the visualizer repository I’ve prepared here: https://github.com/LoshkinOleg/DFT_There_And_Back_Again
Then, generate a Visual Studio solution (or a solution for whatever IDE you’re using) using CMake:

Make sure to make an out-of-source build located under “/build” as illustrated above, it’s required for all the relative paths to be correct. Then open the solution, define the “Application” project as the default project and try compiling the application:
The code should compile without errors but throw a runtime error about not finding the .dll file for SDL:
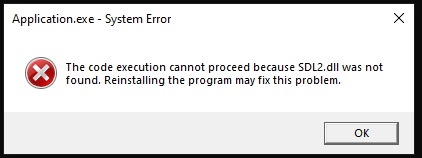
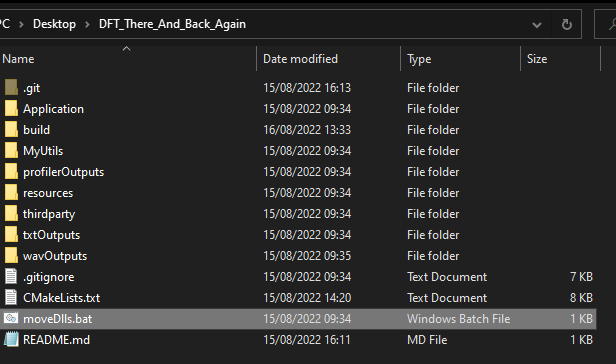
You can use the “/moveDlls.bat” script to automatically move the required .dll files from “/thirdparty/” subdirectories to “/build/Application/bin/Debug/” and “/build/Application/bin/Release/”:
The visualizer should now work:
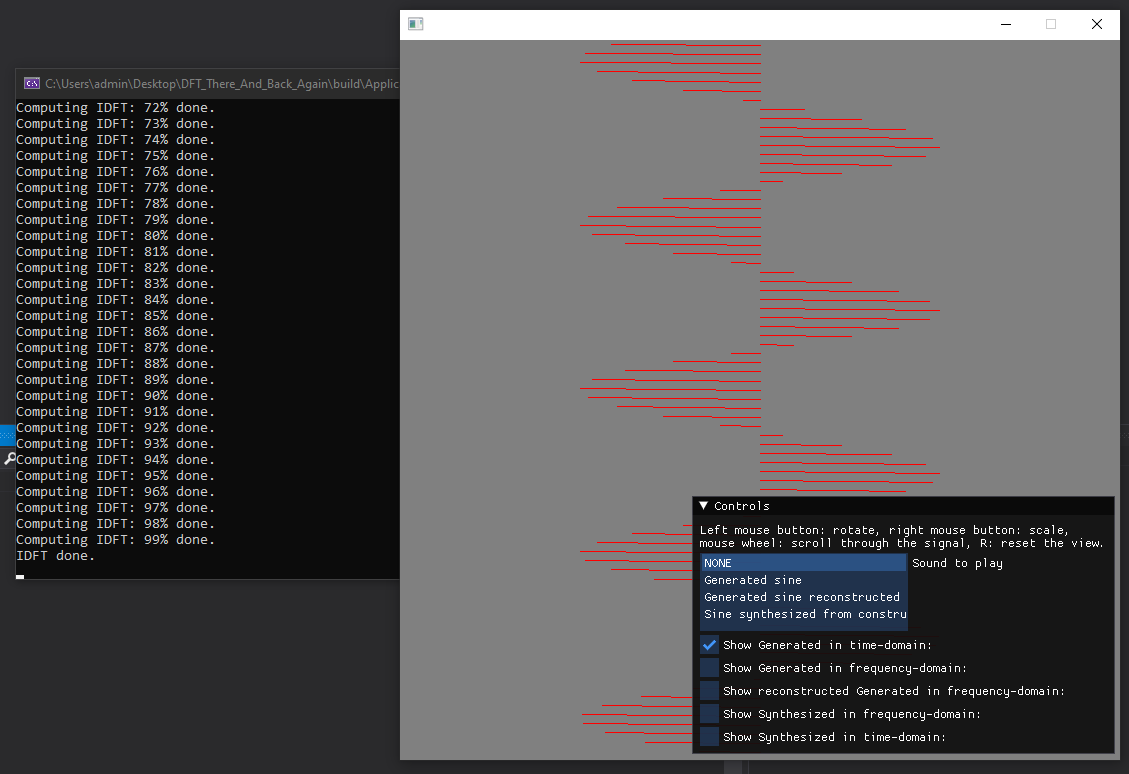
Feel free to mess around with the visualizer to inspect / hear the various signals we’ll be recreating. Once you’re done looking around, close the application and go into the main.cpp file located in the “Source Files” of the “Application” project:

This is where main is defined, and as you can see, it just initializes and runs the Application class defined in “Application/include/Application.h”. This is where you can switch between the working implementation of the DFT defined in “Application/include/FunctionalVisualization.h” and a dummy non-functioning implementation defined in “Application/include/ExerciseVisualization.h”. To do so, simply comment out “#include “FunctionalVisualization.h”” and uncomment “#include “ExerciseVisualization.h””. If you launch the application again now, you should no longer be able to listen to the sines nor visualize them (you’ll just have silent signals). This is because now, you’ll be implementing your own version of DFT in “Application/include/ExerciseVisualization.h”! You can now open the file and have a look. I’ve already written all the boring and irrelevant parts and have marked the places where you should be writing your own code with “// TODO: ” like so:

First let’s walk quickly through the contents of the file. At the top are some commented literals you can use to parameter what kind of signals will be generated by the code below. I’d suggest leaving it at their default values until you’re done writing a working implementation for the visualizer. Next are the signals that the visualizer will be working with:
-
generatedTimeDomain is a time domain signal that you will be generating using a C/C++ standard library’s sin() function. If you leave the literals unchanged, this function should contain a 1 second long, monophonic signal of a 440 Hz sine, sampled at 8’000 Hz. It is a vector of reals.
-
generatedFreqDomain is the variable that will be storing the frequency-domain representations of the same signal as it is output by the DFT function. It is a vector of complex numbers.
-
generatedTimeDomainFromDFT is the time-domain signal that will be storing the time-domain signal reconstructed from generatedFreqDomain via the IDFT function. It is a vector of reals.
Note that for debugging purposes, upon every execution of the application, it outputs generatedTimeDomain, generatedTimeDomainFromDFT and synthesizedTimeDomainFromDFT as 32-bit float, 8’000 Hz sampled .wav files under “/wavOutputs”. You can load those in a DAW, such as Audacity to inspect the signal as it is before going through the whole pipeline that brings a signal from your code to the speakers. It also outputs generatedFreqDomain and synthesizedFreqDomain as .cpp files to “/txtOutputs/” as C arrays for the same purposes:

Then comes the GenerateSine function. As its name indicates, it is used to generate the samples of a pure tone. Afterwards, the EulersFormula is used to apply Euler’s identity described earlier in this blogpost. Next come the centerpieces of the exercise: the DFT and IDFT functions. In them, implemented already are some aliases that will hopefully make it more obvious which function parameters relate to what variables in the mathematical functions presented above as well as some code to print the algorithm’s progress to the console window since the base DFT and IDFT algorithms are quite slow. Finally, GenerateSignals is the function called upon the start of the Application class. You should call the above functions from within it.
The goal of this exercise is to:
-
Generate a SINE_FREQ Hz sine signal sampled at SINE_SAMPLE_RATE to be able to visualize it in the application by checking the “Show Generated in time-domain” checkbox in the visualizer’s menu and to hear it by selecting “Generated sine” in the “Sound to play” field of the visualizer’s menu.
-
Compute the frequency-domain representation of the same signal by implementing the DFT function to be able to visualize it in the application by checking the “Show Generated in frequency-domain” checkbox.
-
Compute back the original time-domain signal from the previously computed frequency-domain representation via the IDFT function and make sure that the thusly reconstructed signal and the original signal is indeed the same one. It can be visualized by checking the “Show reconstructed Generated in frequency-domain” checkbox in the application and can be listened to by selecting “Generated sine reconstructed” as the “Sound to play”.
I encourage you to give it a try yourself at first and come back to this blogpost if you’re stumped. Of course, there’s a fully functional version of the code in “/Application/include/FunctionalVisualization.h” if you’re REALLY stuck, but I suggest you leave that file alone until you’re done with your own working implementation. Hopefully, once you’ve done all of this, you’ll have some more profound understanding of what actually happens under the hood of those magical looking signal processing libraries. A quick disclaimer however, in practice, the DFT and IDFT as we’ll be implementing it here is never used as is. Instead, signal processing libraries always implement one variation or another of the Fast-Fourier Transform (FFT) and the Inverse Fast-Fourier Transform (IFFT), somewhat similar but A LOT more optimized versions of the algorithm we’ll be implementing here. I highly encourage you to watch 3Blue1Brown’s excellent video on the subject if you’re interested.
So, without further ado, let’s get started!
Generating a Sine

“Gandalf” by John Loren
Let’s start with the easy stuff first: let’s generate a pure tone by calling GenerateSine from GenerateSignals:

And move to implementing GenerateSine:
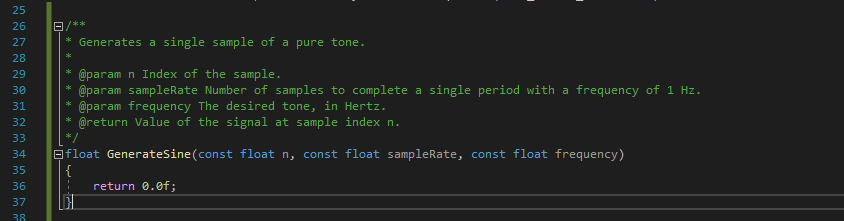
The goal of this function is for a given sample at an index n to return the amplitude that a pure tone at the specified phase offset n would have, for a given sampling rate.
Let’s start simple and simply “return std::sinf(n)” to see what happens:

Sounds and looks promising. But is it actually a 440 Hz pure tone? Let’s open the generated file “/wavOutputs/generated.wav” in Audacity to see what is the frequency of the generated tone:

Ah, not quite. The tone we ended up with seems to be one around 1280 Hz instead. This makes sense if we look at the plot of a pure sine wave on a website like Desmos:

If we consider that every n passed to the GenerateSine function is a positive integer going from 0 to 8’000 (our sample rate), we can indeed see that we end up with around 6 samples per period, just like we see in our visualizer and in Audacity. So we need to adjust the input of the std::sinf function. Let’s start by trying to generate a 1 Hz signal: if we know what the parameters are for a unit frequency, we can then just multiply them to obtain a sine of whatever frequency we desire. Let’s see what happens if we divide n by the sampleRate such that we “return std::sinf(n / sampleRate)”. Surely, we should end up with one long signal that over the span of one second does a full cycle, right?:

No, still not right. The signal varies much slower, but too slow. Why is that? Let’s hunt for some hints on Desmos:
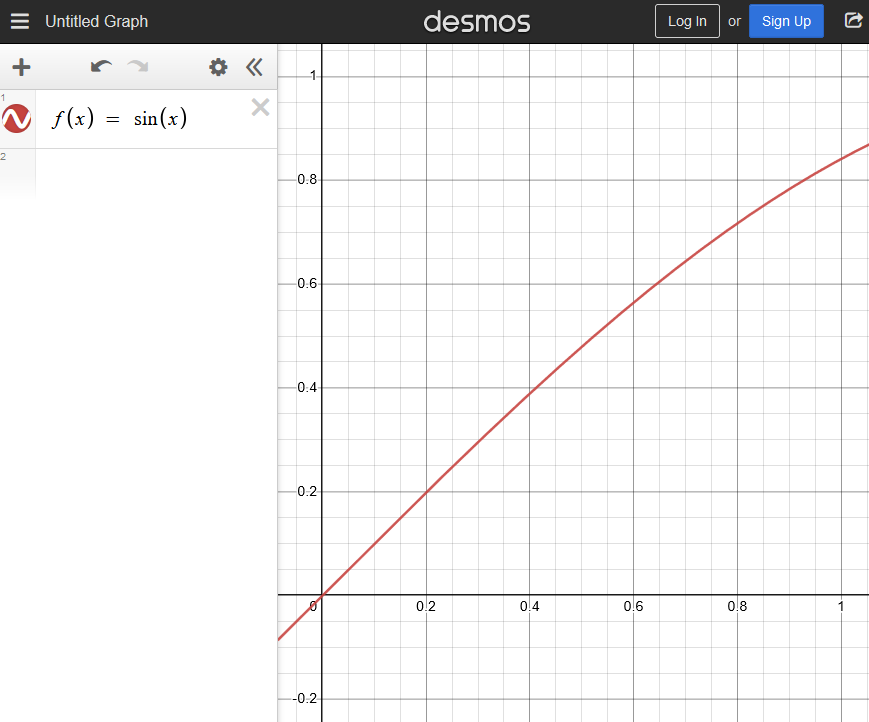
Doesn’t the sine wave in the range x = [0,1] look suspiciously similar to the waveform we’ve ended up in Audacity? Of course it does: this is because we have indeed “normalized” our “n” parameter by dividing it by the sample rate, but we still need to multiply the input of the “std::sinf” function by something that would bring one full period of the sine into the range [0,1]. What could that factor be? Well, isn’t a full revolution around the unit circle just “2*pi”? Let’s try it out:


And perfect! Now, all we need is multiply all of this by the desired frequency and we’re all good!:



Computing the DFT

“Gandalf Fighting Orcs” by Suc-of
Now that we’ve familiarized ourselves a bit with the workflow of the exercise and have a basic sine wave, let’s get to the core of this blogpost: implementing the DFT, the “magical” algorithm that allows us to take real-valued time-domain signals are transform them into this bizarre, complex-valued frequency-domain version of them that is so useful to many signal processing techniques.

The function already contains some code to allow you to print the progress of the algorithm since, as you’ll see yourself later when you launch the program, simple DFT is quite unoptimized. As a reminder, the DFT is defined by the formula:
I’ve named the parameters of the function accordingly and have also defined some aliases so that it is clear which parameter corresponds to what variable in the equation. First of all, the equation comprises a sum, which in code is translated as a for loop:
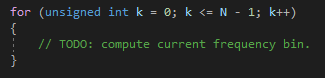
Good, let’s try writing the part of the formula that defines one element of the sum:
![]()
Wait a second. What is the “n” in “x[n]”? We know that “x” is our input time-domain signal, but “n”? Well, “n” is the index of sample being processed in order to give us a single “y[k]”, a single frequency bin. So we’d need to do the same operation for all the samples of our time-domain signal. This means that our frequency-domain signal will have the same length as the input time-domain signal, but with complex numbers instead.
All of this means that in the implementation, we would actually need a second, nested for-loop in order to account for the effect of every sample of the input signal on the current frequency bin:

So, let’s try computing a single element of the sum again:

And… well, that’s it for this function. Let’s implement EulersFormula and we should be good to go:

Mind-blowingly difficult, isn’t it? Let’s give it a try!:
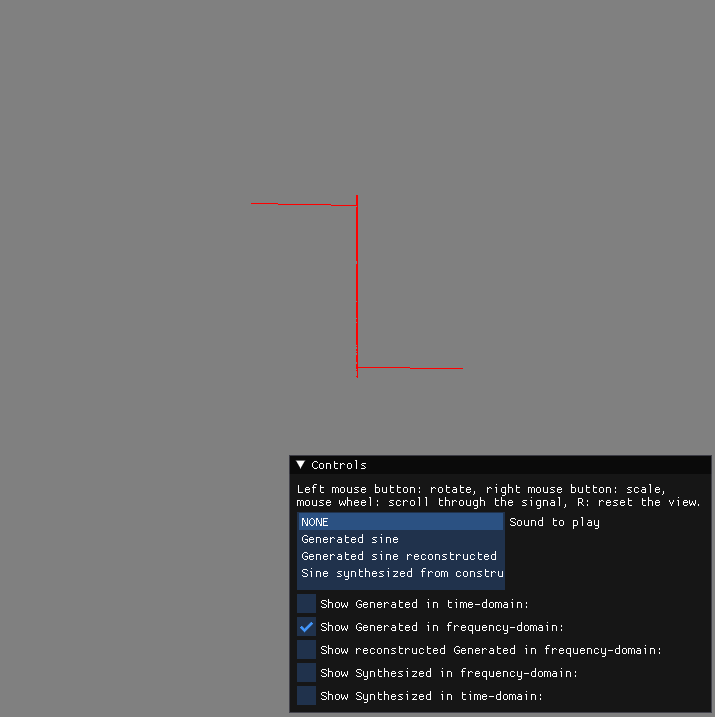
Well, we do have something… but does it make sense? A single frequency bin of the DFT should act as an analysis function, one that reacts strongly to the presence of an expected pure tone. I highly encourage you to check out 3Blue1Brown’s excellent visualization of this.
Let us think for a moment: what is the content of the vector containing the DFT? It is a series of frequency bins arranged such that as the index of the frequency bin increases, the frequency bins associated with the growing indices are ones that are sensitive to pure tones of growing frequencies. For instance “y[10]” would be sensitive to a 10 Hz pure tone, “y[100]” sensitive to a 100 Hz pure tone and so on. In our visualizer, the signals are drawn from bottom to top, with frequency bins sensitive to lower frequencies placed towards the bottom of the frequency-domain signal and the ones sensitive to higher frequencies placed towards the top. Considering that we’ve generated a 440 Hz pure tone and that the length of both of our time and frequency domain signals is 8’000 (our sampling rate), it almost makes sense to see the resulting graph.
There’s just one strange detail: why two peaks, one at the top in one way and another at the bottom in the other way? Let’s take a look at the values of our DFT output by inspecting the “/txtOutputs/generated.cpp” file that the Application has generated for us at startup. It contains a C array of complex numbers of length 8’000:

As expected, we do indeed see a spike at 400 Hz (remove 2 from the line number since the first line is taken by the array declaration and the text editor starts at 1 instead of 0) and the neighboring frequency bins remaining at approximately 0 as one would expect. Interestingly though is that the value of the imaginary component is 4’000, half the sample rate. It does make sense for this value to be large: the DFT takes into account not only the frequency but also “how long” the pure tone is sustained through time. But why only half? Let’s look at the other end of the array:

And indeed, here we see the remaining magnitude that together with the 440 Hz would bring us to a value of approximately 8’000. It is contained in the 8000 - 440 = 7560 Hz frequency bin, but the complex number’s argument is (almost) perfectly opposite to that of the 400 Hz bin. To understand what is happening, I invite you to read through Jim Clay’s answer to this stackexchange post:
“Another way to think about it:
Imaginary components are just that.. imaginary! They are a tool, which allows the employ of an extra plane to view things on and makes much of digital (and analog) signal processing possible, if not much easier than using differential equations!
But we can’t break the logical laws of nature, we can’t do anything ‘real’ with the imaginary content. And so it must effectively cancel itself out before returning to reality. How does this look in the Fourier Transform of a time based signal(complex frequency domain)? If we add/sum the positive and negative frequency components of the signal the imaginary parts cancel, this is what we mean by saying the positive and negative elements are conjugate to each-other. Notice that when an FT is taken of a time-signal there exists these conjugate signals, with the ‘real’ part of each sharing the magnitude, half in the positive domain, half in the negative, so in effect adding the conjugates together removes the imaginary content and provides the real content only.”
To be perfectly honest with you, I don’t quite understand it myself yet, so for now, let’s simply take this mirroring phenomenon for granted. Note however that thanks to this symmetry, one does not necessarily need to compute the full 8’000 range of frequency bins: we could instead compute only the frequency bins from 0 to 3’999, double their magnitude and leave the remaining frequency bins at 0+0i. Doing so will alter the frequency-domain representation of the signal, but once converted back to the time-domain, both frequency-domain signals would result in the same time-domain signal:

But we’ll keep the code as is for now though, for simplicity’s sake.
The Inverse Fourier Transform

“Gandalf returns from the dead as Gandalf the White” from “Lord of the Rings: The Two Towers” (2002) retrieved from: https://www.quora.com/Is-Gandalf-the-White-still-an-Istar .
Well, this “magical” frequency-domain realm of signal is very interesting, but how do we go about going back? While frequency-domain signals are very useful, we cannot directly listen to them.
To go back, we simply have to apply the Inverse Discrete Fourier Transform to the frequency-domain signal, which I’ll be referring to as “IDFT” from now on. As an analogy, we know that if we move a cup of coffee from the counter to the table (meaning we’re applying a translation transformation on the object), we can always move it back to the counter (meaning we can apply the inverse of the transformation to end up with the original scenario). The same is true with the Fourier Transform and the Inverse Fourier Transform, all we need is to do the opposite of what we’ve done initially, like tracing back one’s own path.
So let’s try to write the IDFT then! Firstly, since for the DFT we had a sample iterating for-loop nested inside a for-loop that is iterating over the frequency bins, for the IDFT, we do the opposite:
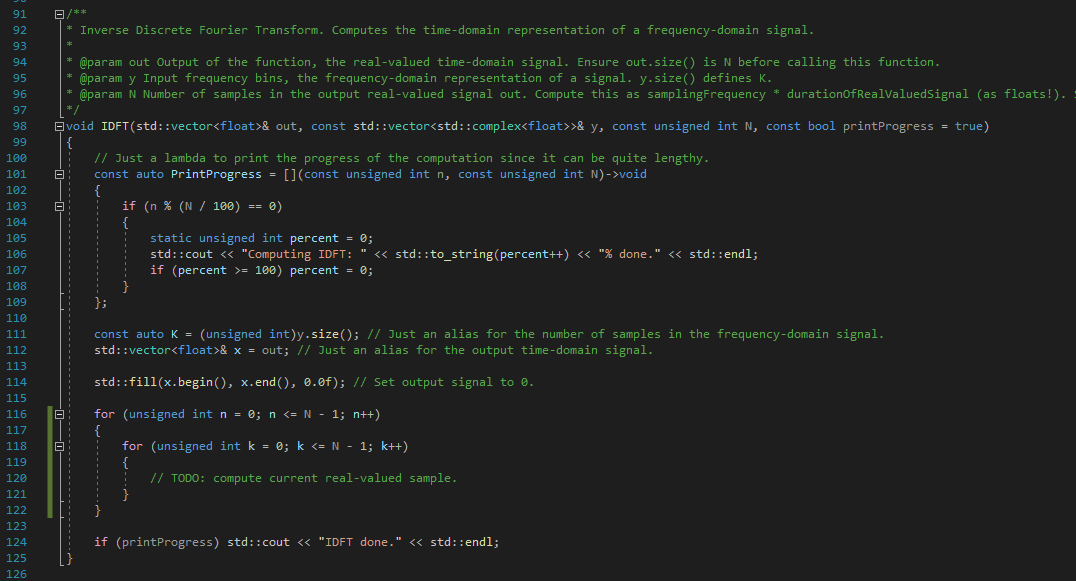
Next, since for the DFT we’ve multiplied a real-valued sample by:
![]()
This effectively “winds” the signal around the origin in the Argand plane in a counter-clockwise fashion. To undo this, we’ll multiply a complex-valued frequency bin by:
![]()
This will effectively “unwind” the signal from the complex plane, back into the domain of reals. I invite you to check out Diego Unzueta’s excellent article explaining this “winding” concept. Finally, since we’re only interested in the real component of the resulting multiplication, we’ll store only the real part of the resulting complex number:

Let’s give it a listen… oh my! It just sounds like white noise once it has gone through our DFT -> IDFT transformations… yet the visual representation looks correct!:

Okay, I have to admit that I have inadvertently slightly deceived you here with my visualization, if we open “/wavOutputs/synthesizedFromDFT.wav” in Audacity, you might get a bit of a better ideas of what might be going on:

The samples we’ve generated seem to be way out of the [-1;1] range that a playback device (such as your headphones) expect!:

That much was not immediately obvious in my visualizer since it automatically scales the signals we’re trying to visualize so that they fit on screen. In reality, the two sine signals displayed a few images above have a matching frequency and phase but have very different amplitudes.
This is a good reminder that even if graphical tools are great to wrap one’s mind around a complicated concept, there’s nothing that can replace a good ol’debugger!
But back to our problem, why are the samples so out of range? Haven’t we done everything in exactly the reversed way? Shouldn’t we end up with the original signal? Well, remember when I mentioned that the DFT spits out a frequency bin that not only represents whether a particular frequency is present in the complex sound but also represents for “how long” the signal persists? This is the origin of our mistake: we haven’t scaled the signal back down. Let’s take a look at the actual equation of the IDFT:

We almost had it! We just need to divide the resulting sample by the length of the signal:

Note that I’ve clamped the resulting value to the range of [-1;1], this is not to normalize the signal (the division by N takes care of that) but to ensure that any floating point imprecisions do not result in values that are just barely above or below 1 and -1 respectively, which causes the samples to wrap around back into the negatives and positives respectively. You can remove this line of code and see it for yourself by inspecting the .wav file in Audacity.
And voilà!
To Sum Things Up

“The Shire” by Chase Henson.
In this little journey together, we’ve learnt more about how a time-domain signal can be transformed into its frequency-domain representation and back again, hopefully in a manner that has helped you to demystify these transformations. This deceivingly “complicated” tool has revolutionized many domains of science and engineering, not only that of Digital Sound Processing: in fact, Fourier has formulated his now famous formulae while trying to solve the heat equation which describes the way heat propagates through a solid. Today, it is a tool used in practically every field of engineering, from image processing to quantum mechanics.
This is of course only the start, and there’s plenty of things left to explore on your own now that you understand the basics, even in the functions we’ve implemented here together. I invite you to explore these questions for yourself to better understand what’s going on:
-
What happens if the sizes of the time-domain signal and the frequency-domain signal are mismatched?
-
Knowing what you do now, can you construct a frequency-domain signal yourself that would result in an arbitrary pure tone of your choice? You can use the synthesizedFreqDomain and synthesizedTimeDomainFromDFT vectors to try that out.
-
How would you go about making the same transformations we’ve done together but applied to a pure tone sound signal that lasts 2 seconds instead of 1? What about one that lasts 30 seconds?
-
How does varying the sampling rate affect the result of the DFT? Should it?
-
Can you think of ways to make the computation of the DFT and IDFT more optimized without looking into how the FFT and IFFT works?
-
What happens if instead of working with a pure tone as has been the case here, you work with complex sound? A ⅓ to ⅔ mixture of a 440 Hz and a 880 Hz signals for instance?
The visualizer provided as part of this blogpost will hopefully make it less frustrating to explore these questions, but if you do encounter some bugs or don’t understand some behavior of the code, do feel free to poke around in it, everything has been properly commented to help you understand how the visualizer works.
I hope you’ve enjoyed this little trip to the frequency domain and back and stay curious!

“Thorin and Company at Bilbo Baggins’ Burrow” by an unknown artist, credited to “Warner Bros.”, retireved from: https://www.thekitchn.com/a-menu-for-a-hobbit-party-214322 .